skip to main |
skip to sidebar
 I read a rare article about cataloging accuracy (or the lack of it) from outside the field today. Of course this is old news to librarians, but it's one more reminder that skimping on the fundamentals always comes back and bites you in the end (er, I mean eventually).
I read a rare article about cataloging accuracy (or the lack of it) from outside the field today. Of course this is old news to librarians, but it's one more reminder that skimping on the fundamentals always comes back and bites you in the end (er, I mean eventually).
This image is one of my favorite movie scenes-- it's from "Raiders of the Lost Ark", when the U.S. government stores the Ark in an unfathomably vast warehouse where it will probably be lost for another two thousand years. It always reminds me of a library, somehow.
Christopher Blizzard has posted a newsy update to his blog detailing progress on developing the 2B1 One Laptop Per Child device.
You can read all about it here.
They seem to be making rapid progress, although with pre-production models due for testing in the wild (i.e. real children!) in just a few months, they had better!
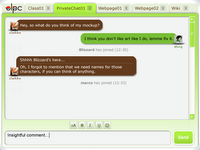 Sugar is the new interface for the OLPC laptops. Rather than simply using Gnome or some established Linux front end, the folks at the OLPC decided to desgn their own interface incorporating tools to assit if the educational and social-computing goals of the project.
Sugar is the new interface for the OLPC laptops. Rather than simply using Gnome or some established Linux front end, the folks at the OLPC decided to desgn their own interface incorporating tools to assit if the educational and social-computing goals of the project.
For example, Mesh View is a way of displaying the active laptops in the mesh network-- the peer to peer wireless network the units generate.
Friends View allows users to add and remove friends and invite them to participate in activities with a few clicks.
Other collaborative software will include the widespread use of Wikis.
If only the software we adults use permitted that kind of easy collaboration!
 Another comment from the discussions going on in the Next Generation Catalog listserv:
Another comment from the discussions going on in the Next Generation Catalog listserv:
"THAT seems to me like a major component of findability—not getting you to the book faster, but finding what you wouldn't otherwise find."
EXACTLY-- I've been thinking about OPAC browsing all day since reading that the Evergreen team is thinking about modeling a browse feature on the one used by the Barnes and Noble web site. But my most successful browsing experiences always seem to involve some serendipity or randomness. I wonder if there is a way to harness this?
For example, StumbleUpon works because they collect the "thumbs up" search results of members and associate the sites with tags. So StumbleUpon searches provide a theoretically more productive web browsing experience. Why couldn't a library discovery tool collect "thumbs up" or "thumbs down" responses from users on catalog searches, and associate them with the search terms that were used so as to create a similar improved browsing experience?
One forthcoming discovery product, Innovative Interfaces' Encore, is already going to keep it's own database of patron-supplied tags for the items in the OPAC. It could similiarly build a database of search terms and results.

If you thought Foss was one of the sons on "Bonanza", you've obviously never seen a celebration of Software Freedom Day, a day devoted to promoting the use of Free and Open Source Software (FOSS). Each year dozens of schools, clubs, and other "grass-roots" groups use the opportunity to set up booths in malls, campuses, or other public places to spread the word about FOSS. This year, the day was celebrated today.
[Note from Monday: Check out the site-- pictures from this year's activities from around the world are already being posted.]
I started thinking about how libraries now have a year to think up ways to promote the next one. Linking up with local FOSS supporters to host a both is one way, of course. But two other possibilities come to mind:
One of SFD's sponsors is The Open CD, a wonderful collection of free software made to be freely distributed. The programs run in Windows and cover the most common tasks such as word processing, presentations, e-mail, web browsing, web design, and image manipulation. The Open CD team only includes software they consider appropriate for a wide audience, and each program is carefully tested for stability. These CDs can be burned for simply the cost of the blank disc and would make a perfect promotional item for a computer literacy-related library event or as a prize for a Summer Reading Program.
Finally, I thought of the Freedom Toaster, a freestanding kiosk designed to burn discs of free software for people or areas without broadband Internet access where downloading over the 'net would be problematic. The specs are posted online, and the machine can look as nice as you want or can afford. The handsome one pictured here obviously represents an investment in time and materials, but would make quite a statement of support both for free software and towards narrowing the digital divide.
I think these are all as good a promotional opportunity for libraries as National Library Week.
 Several years ago students in a graduate class at the University of Georgia wrote the first version of the free e-textbook "XML: Managing Data Exchange". Later classes at U Georgia and elsewhere have improved and extended the book. Each class using the textbook has been required to leave it in better shape than they found it.
Several years ago students in a graduate class at the University of Georgia wrote the first version of the free e-textbook "XML: Managing Data Exchange". Later classes at U Georgia and elsewhere have improved and extended the book. Each class using the textbook has been required to leave it in better shape than they found it.
This has inspired the University of Georgia's Center for Information Systems Leadership to launch the Global Text Project (http://globaltext.org), a project to harness the creativity of college students to create open content e-textbooks for use by other students around the world.
Similar to WikiBooks, the Global Text project is interesting because much of the work will be generated by students in the supporting institutions as class assignments. Guided by faculty and editors from the project, the books will initially be produced in English and Chinese, with translations to Spanish and Arabic appearing later. The goal is to create a library of 1,000 open content electronic textbooks that will be freely available from a Web site. Distribution will also be possible via paper, CD, or DVD.
Although much of what I wrote in college was hopeless dreck, I did learn to synthesize original research, which is what textbooks do. College students produce thousands of papers on thousands of topics each year, and all of this just gets thrown out. With proper editing and guidance (and motivation), this could be an important resource. I think this is an exciting read-write culture moment.
 For the last week, the "Next Generation catalog listserv" has been buzzing with discussions of what is needed to bring library catalogs into the modern era. Listserv participant Karen Coyle describes the need to "Murder MARC" as part of the process. But I'm afraid that when MARC goes, it may be a suicide.
For the last week, the "Next Generation catalog listserv" has been buzzing with discussions of what is needed to bring library catalogs into the modern era. Listserv participant Karen Coyle describes the need to "Murder MARC" as part of the process. But I'm afraid that when MARC goes, it may be a suicide.
Our cataloging process is as broken as our cataloging format. We need to rethink the idea of 1,000 catalogers maintaining 1,000 separate versions of the same OCLC or LC-sourced MARC record in 1,000 separate local catalogs. One can see signs that this model is failing in the declining quality of new original cataloging and in the increasing use of non-updated "raw" CIP records in catalogs. We used to worry that too many cataloging decisions were being made by paraprofessionals-- now many decisions aren't being made at all.
There is another model of sharing and updating files (which is really what modern cataloging is). The cooperative teams behind Open Source software programs use version control systems to manage the updates (bug fixes, new features, etc.) going into the program's code from programmers all over the world. Maintainers work to ensure the updates work as promised and don't create more problems. Once the maintainers sign off on a new release, it goes off to data repositories and from them to users around the world.
In this system, the changes made by the contributors are made against a master copy that is then shared with everyone. The same problem is not fixed 1,000 times for each local installation-- it is fixed once, and the next 999 contributors can work on the next 999 problems.
What if library cataloging worked this efficiently? Because most enhancements or corrections are currently made by hand at the local level, there is a massive amount of duplicated effort. A new model which uses technology to eliminate this waste could allow the labor to go into quality control or other activities where catalogers are needed (that special collections cataloging backlog, for example).
As the debate about the post-MARC format rages on, we must remember that sustainability is at least as important as functionality-- and we just can't afford to maintain the traditional cataloging model.
 Today the Georgia PINES consortium (Public Information Network for Electronic Services) has launched Evergreen, their new Open Source ILS.After two years of development, Evergreen has gone live. Designed for use by a 252-library consortium with combined collection of 8 million volumes, it represents a considerable move up-market for Open Source ILS software. (Koha's largest installation is the seven branch Nelsonville Public Library in Ohio with 250,000 volumes)
Today the Georgia PINES consortium (Public Information Network for Electronic Services) has launched Evergreen, their new Open Source ILS.After two years of development, Evergreen has gone live. Designed for use by a 252-library consortium with combined collection of 8 million volumes, it represents a considerable move up-market for Open Source ILS software. (Koha's largest installation is the seven branch Nelsonville Public Library in Ohio with 250,000 volumes)
Evergreen looks like a polished, production ILS. It has an initial social web feature in its "Bookbags", which alllow patrons to create reading lists and share them with friends. The "To Do" list on the developer site mentions a proposal to emulate the browse capabilities of the Barnes and Noble site.
Koha has an active group of supporters around the world who have steadily grown the product and expanded its usefullness far beyond the modest initial product. The key step now is for a development community to grow around Evergreen.
The Evergreen documentation wiki has a lot of information on the project, including demos, presentations, and training modules.
 The One Laptop Per Child device has its production name: the 2B1
The One Laptop Per Child device has its production name: the 2B1
Lesser known in the West perhaps than its laptop features is the fact that the screen is designed to pivot around so it can be used as an ebook reader. The potential to replace printed textbooks with cheaper e-textbooks is an important consideration in funding the purchase of these machines. See the discussion here.
If successful, the 2B1 will clearly change schools, but I think that it may also change libraries. E-textbooks have always seemed to me to be a perfect "killer app" for electronic publishing-- textbooks are read for facts, not narrative, and are a required purchase, not a choice. Further, they are required by institutions that would also be in a position to dictate the model of hardware reader. The 2B1 could become the standard, low-cost reader the market has needed all along. Once people own a standard reader, they might be willing to read more in electronic form.
Which leads to libraries. Here we are, slowly (perhaps too slowly) and steadily building our ebook collections, waiting for patrons to catch on. For the first time in years, I think we can see a plausible way that they might do just that.
 I read a rare article about cataloging accuracy (or the lack of it) from outside the field today. Of course this is old news to librarians, but it's one more reminder that skimping on the fundamentals always comes back and bites you in the end (er, I mean eventually).
I read a rare article about cataloging accuracy (or the lack of it) from outside the field today. Of course this is old news to librarians, but it's one more reminder that skimping on the fundamentals always comes back and bites you in the end (er, I mean eventually).






